

MLエクスペリメンテーションのギークガイド
リンク一覧
概要と1. はじめに
1.1 事後説明
1.2 不一致問題
1.3 説明の合意を促進する
-
関連研究
-
Pear: 事後説明合意正則化
-
合意訓練の有効性
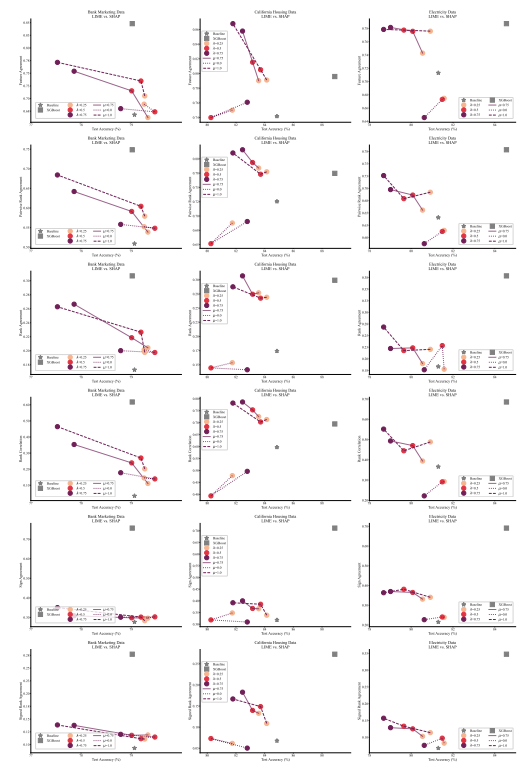
4.1 合意指標
4.2 合意指標の改善
[4.3 一貫性はどのような代償で?]()
4.4 説明はまだ価値があるか?
4.5 合意と線形性
4.6 2つの損失項
-
考察
5.1 今後の研究
5.2 結論、謝辞、参考文献
付録
A 付録
A.1 データセット
実験では、OpenMLから取得し、HuggingFaceのInria-Sodaチームによってベンチマークデータセットとしてまとめられた表形式データセットを使用しています[11]。各データセットの詳細を以下に示します:
\ Bank Marketing これは6つの入力特徴を持つ二値分類データセットで、クラスはほぼ均等に分布しています。7,933のトレーニングサンプルで訓練し、残りの2,645サンプルでテストしました。
\ California Housing これは7つの入力特徴を持つ二値分類データセットで、クラスはほぼ均等に分布しています。15,475のトレーニングサンプルで訓練し、残りの5,159サンプルでテストしました。
\ Electricity これは7つの入力特徴を持つ二値分類データセットで、クラスはほぼ均等に分布しています。28,855のトレーニングサンプルで訓練し、残りの9,619サンプルでテストしました。
A.2 ハイパーパラメータ
多くのハイパーパラメータは全ての実験で一定です。例えば、すべてのMLPはバッチサイズ64、初期学習率0.0005で訓練されています。また、研究対象のすべてのMLPは、各100ニューロンの3つの隠れ層を持っています。常にAdamWオプティマイザ[19]を使用しています。エポック数はケースによって異なります。3つのデータセットすべてにおいて、𝜆 ∈ {0.0, 0.25}の場合は30エポック、それ以外の場合は50エポックで訓練しています。線形モデルを訓練する場合は、10エポックと初期学習率0.1を使用しています。
A.3 不一致指標
本研究で使用した6つの合意指標をここで定義します。
\ 最初の4つの指標は、各説明における上位𝑘個の重要な特徴に依存しています。𝑡𝑜𝑝_𝑓 𝑒𝑎𝑡𝑢𝑟𝑒𝑠(𝐸, 𝑘)を説明𝐸における上位𝑘個の最も重要な特徴、𝑟𝑎𝑛𝑘 (𝐸, 𝑠)を説明𝐸内での特徴𝑠の重要度ランク、𝑠𝑖𝑔𝑛(𝐸, 𝑠)を説明𝐸における特徴𝑠の重要度スコアの符号(正、負、またはゼロ)とします。
\ 
\ 次の2つの合意指標は、上位𝑘だけでなく、各説明内のすべての特徴に依存しています。𝑅を重要度によって説明内の特徴のランキングを計算する関数とします。
\ 
\ (注:Krishna et al. [15]は論文で、𝐹はエンドユーザーによって指定される特徴のセットであるとしていますが、我々の実験ではこの指標ですべての特徴を使用しています)。
A.4 ジャンク特徴実験結果
セクション4.4の実験でランダム特徴を追加する際、特徴の数を2倍にしました。これは、合意損失が、自然に訓練されたモデルよりも頻繁に無関係な特徴を上位𝐾に配置することで説明の質を損なうかどうかを確認するためです。表1では、各説明器がランダム特徴のいずれかを上位5つの最も重要な特徴に含めた割合を報告しています。全体的に見て、𝜆 = 0.0(合意損失なしのベースラインMLP)と𝜆 = 0.5(合意損失で訓練されたMLP)の間でこれらの割合の系統的な増加は見られないことが分かります。
\ 
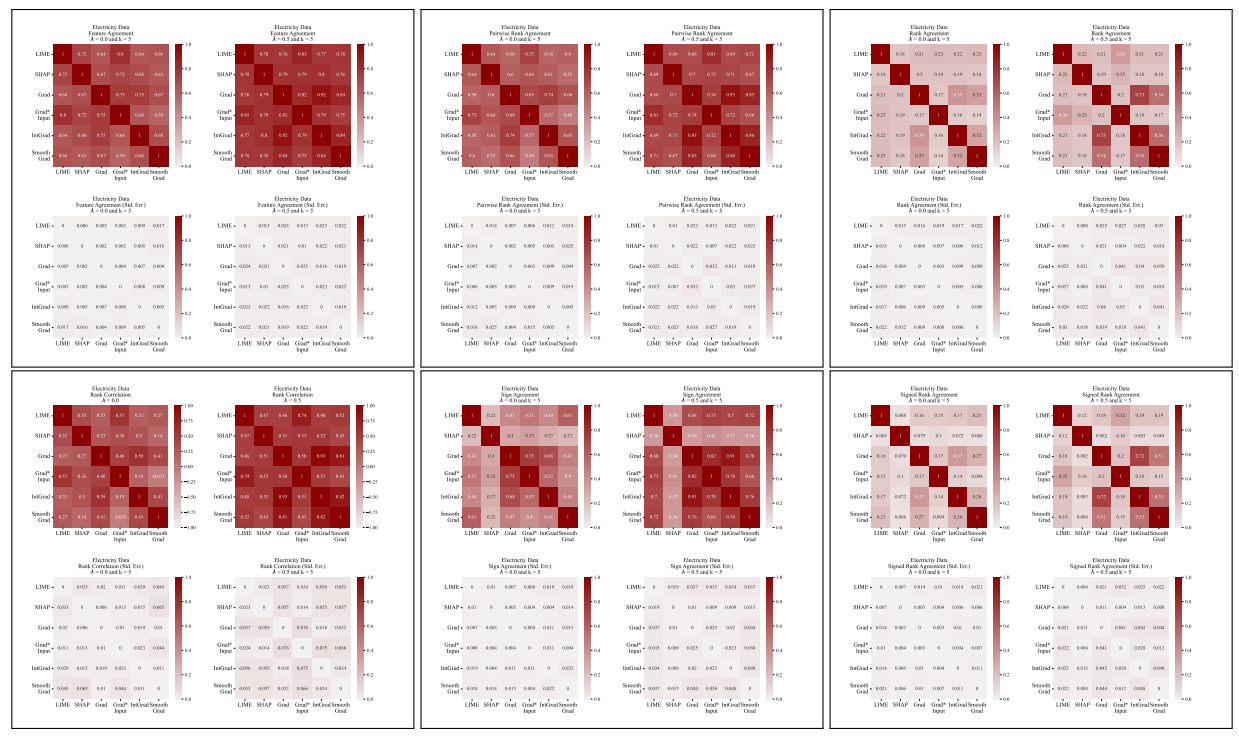
A.5 その他の不一致行列
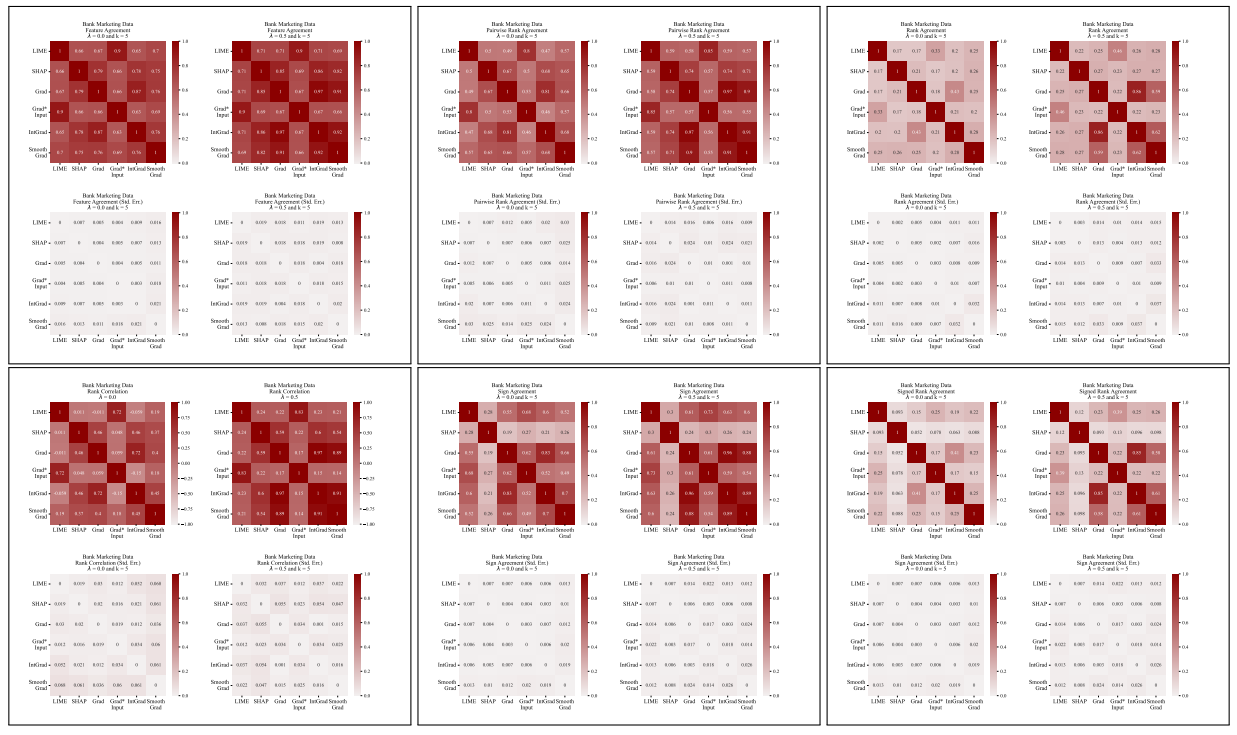
\ 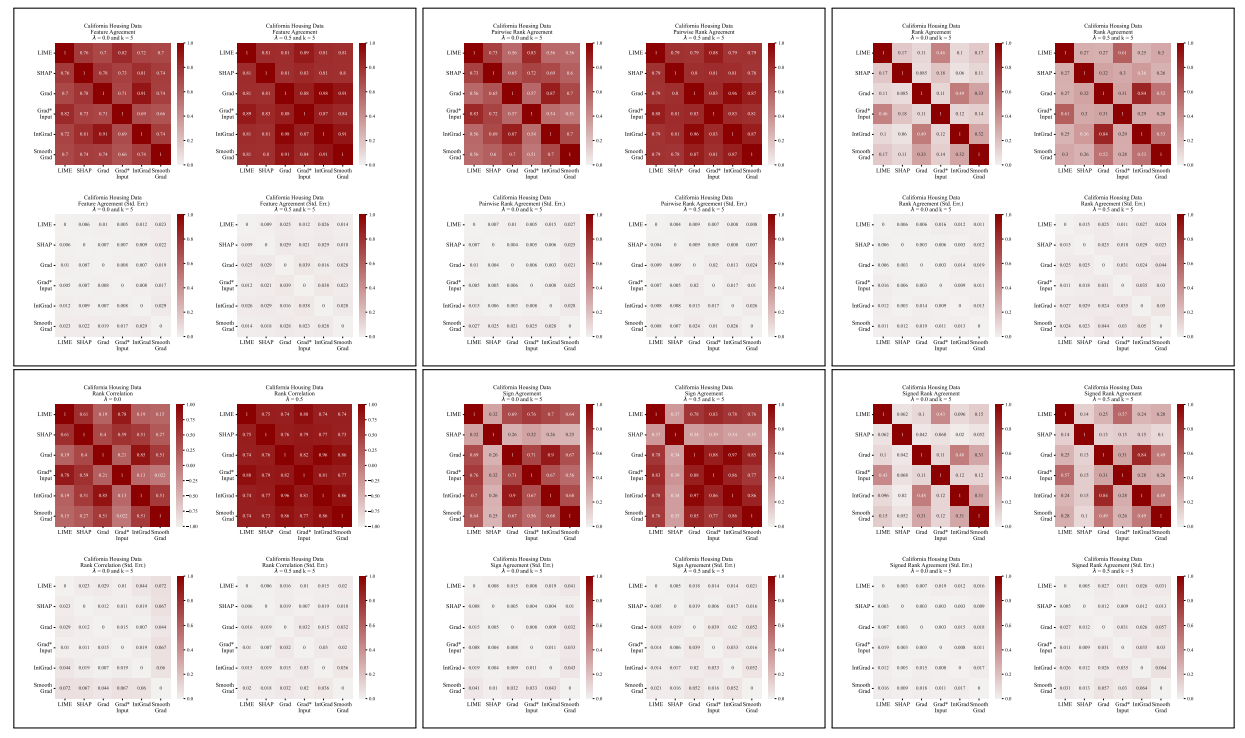
\ 
A.6 拡張結果
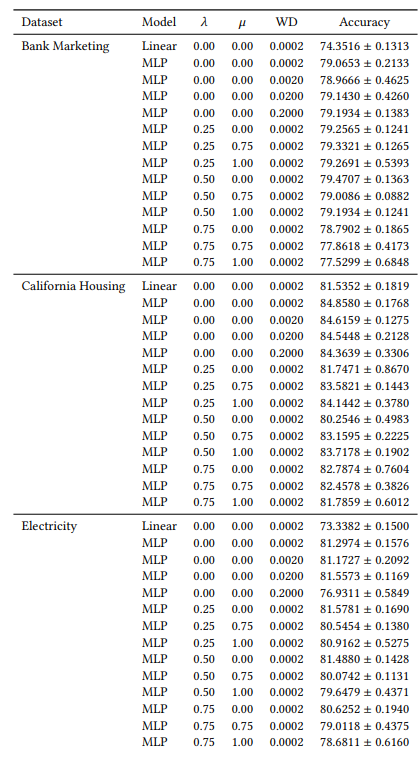
A.7 追加プロット
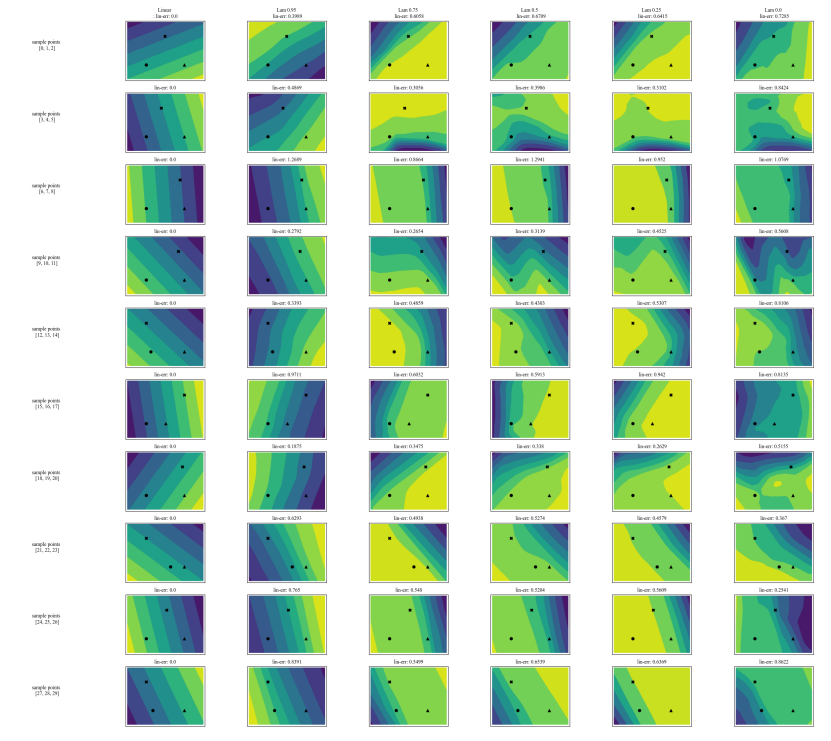
\ 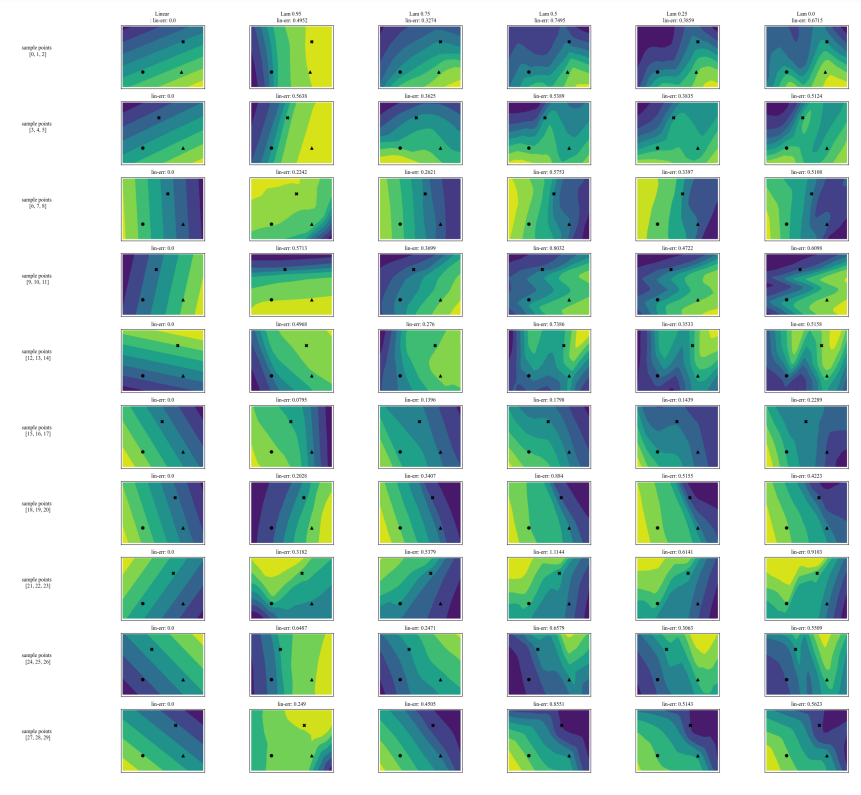
\ 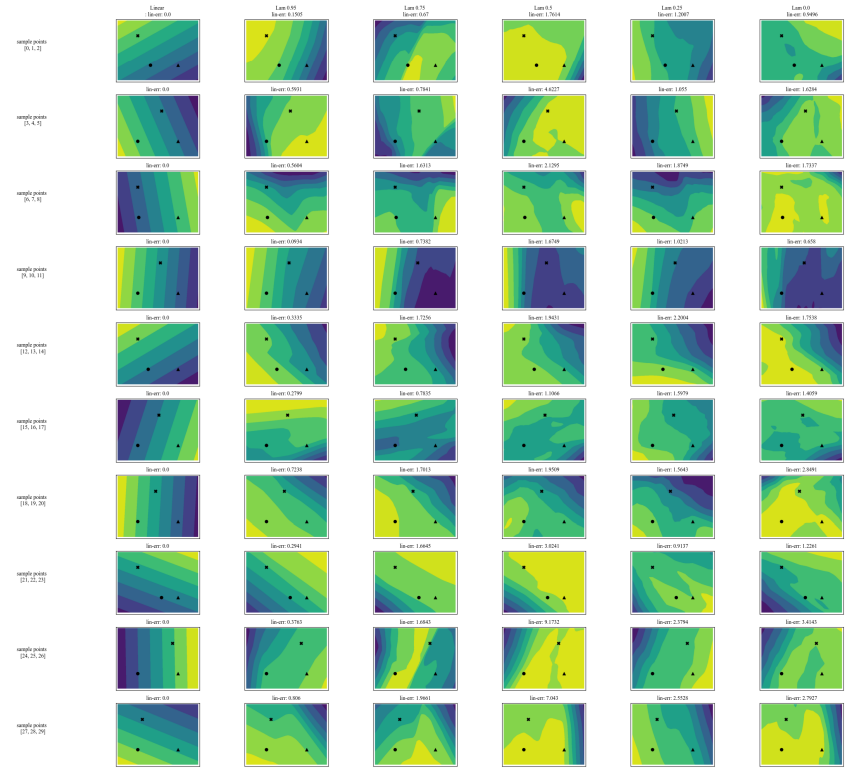
\ 
\
:::info 著者:
(1) Avi Schwarzschild、メリーランド大学カレッジパーク校、メリーランド州、アメリカ合衆国、およびArthurでの勤務中に完成した研究(avi1umd.edu);
(2) Max Cembalest、Arthur、ニューヨーク市、ニューヨーク州、アメリカ合衆国;
(3) Karthik Rao、Arthur、ニューヨーク市、ニューヨーク州、アメリカ合衆国;
(4) Keegan Hines、Arthur、ニューヨーク市、ニューヨーク州、アメリカ合衆国;
(5) John Dickerson†、Arthur、ニューヨーク市、ニューヨーク州、アメリカ合衆国([email protected])。
:::
:::info この論文はarxivで入手可能であり、CC BY 4.0 DEEDライセンスの下で公開されています。
:::
\
関連コンテンツ

先物清算:市場が震える中、1時間で驚異の1億3,900万ドルが消失

予算協議が再び行き詰まり、米国政府が明日閉鎖される可能性 – 知っておくべきこと
