

Predictive Process Monitoring Using Graph Neural Networks
Table of Links
Abstract and 1. Introduction
-
Background and Related work
-
Preliminaries
-
PGTNet for Remaining Time Prediction
4.1 Graph Representation of Event Prefixes
4.2 Training PGTNet to Predict Remaining Time
-
Evaluation
5.1 Experimental Setup
5.2 Results
-
Conclusion and Future Work, and References
\
4 PGTNet for Remaining Time Prediction
To predict the remaining time of business process instances, we convert an event log into a graph dataset (see Section 4.1), and use it to train a predictive model (see Section 4.2). Once the model’s parameters are learned, we can query the model to predict the remaining time of an active process instance based on its current partial trace.
4.1 Graph Representation of Event Prefixes
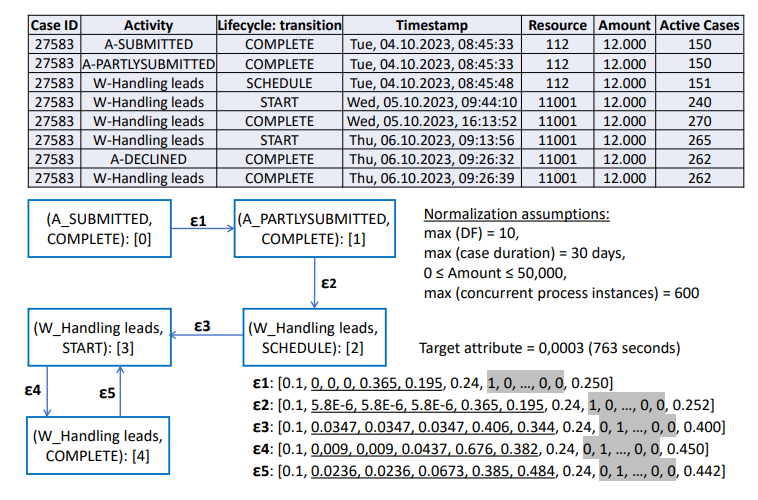
\ 
\ 
\ Edge features. To enhance the expressive capacity of the graph representation, we incorporate additional features into the edge feature vector:
\ – We use five different temporal features per edge. These include the total duration (t1) and duration of the last occurrence (t2) of the DF relation represented by the edge. Similar to other works [17], we also incorporate distances between the timestamp of the target node and the start of the case (t3), start of the day (t4), and start of the week (t5) for the latest occurrence of the DF relation. While t1, t2, and t3 are normalized by the largest case duration in the training data, t4 and t5 are normalized by the duration of days and weeks, respectively. In Figure 1, the temporal features are underlined in the feature vectors of the edges.
\ 
\ – To account for the overall workload of the process at a given time, we capture the number of active cases at the timestamp of the target node (for the last occurrence of the DF relation). This feature is normalized by the maximum number of concurrent process instances observed in the training data.
\ Note that we encode this information as edge features, rather than on the nodes, in order to preserve the simplicity of the node semantics. In this way, PGTNet can also deal with event logs with a large number of event classes, achieved by employing an embedding layer.
\ 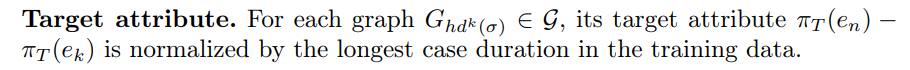
4.2 Training PGTNet to Predict Remaining Time
Once an event log is converted into a graph dataset, it can be used to train PGTNet to learn function θL in Equation 1 in an end-to-end manner. We specifically approach the remaining time prediction problem as a graph regression task, using L1-Loss (mean absolute error between predictions and ground truth remaining times). Model training employs the backpropagation algorithm to iteratively minimize the loss function. For this, we adopt the GPS Graph Transformer recipe [16] as the underlying architecture of PGTNet.
\ PGTNet architecture. PGTNet’s architecture comprises embedding and processing modules, as shown in Figure 2.
\ Embedding modules have two main functionalities:
\ – They map node and edge features into continuous spaces. To ensure that similar event classes are closer in the embedding space, an embedding layer is used to map integer node features into a continuous space. We use fully-connected layer(s) to compress edge features into the same hidden dimension and address the challenges arising from high-dimensional data attributes.
\ – They compress the graph structure into multiple positional and structural encodings (PE/SE), and seamlessly incorporate these PE/SEs into node and edge features [16]. This integration is achieved through diverse PE/SE initialization strategies and the utilization of several learnable modules, including MLPs (multi-layer perceptron) and batch normalization layers, as illustrated in Figure 2.
\ ![Fig. 2. PGTNet architecture: based on the GPS Graph Transformer recipe [16]. Paths to process node and edge features are specified by blue and red colors, respectively.](https://cdn.hackernoon.com/images/null-zj032xh.png)
\ 
\ 
\ Note that edge features are solely processed by MPNN blocks and are not utilized by Transformer blocks or in obtaining the graph-level representation.
\ Design space for PGTNet. The modular design of the GPS Graph Transformer recipe offers flexibility in choosing various types of positional/structural encodings (PE/SEs) and MPNN/Transformer blocks.
\ PE/SEs aim to enhance positional encoding for Transformer blocks [10], and enable GNN blocks to be more expressive [4]. The compression of graph structure into PE/SEs can be achieved through the utilization of various initialization strategies (PE/SE initialization in Figure 2). Notably, Laplacian eigenvector encodings (LapPE) [10] furnishes node embedding with information about the overall position of the event class within the event prefix (global PE), while it enhances edge embedding with information on distance and directional relationships between nodes (relative PE). Random-walk structural encoding (RWSE) [4] incorporates local SE into node features, facilitating the recognition of cyclic control-flow patterns among event classes. Graphormer employs a combination of centrality encoding (local SE) and edge encoding (relative PE) to enhance both node and edge features [24].
\ Additionally, a range of learnable modules for processing PE/SEs can be integrated into PGTNet as highlighted in [16]. These design options include simple MLPs as well as more advanced networks such as DeepSet [25] and SignNet [11]. Lastly, while it is possible to use various MPNN and global attention blocks within each GPS layer [16], we exclusively used the graph isomorphism network (GIN) [9] and conventional transformer architecture [18]. Further details regarding our policy for designing PGTNet are elaborated upon in Section 5.1.
\
:::info Authors:
(1) Keyvan Amiri Elyasi[0009 −0007 −3016 −2392], Data and Web Science Group, University of Mannheim, Germany ([email protected]);
(2) Han van der Aa[0000 −0002 −4200 −4937], Faculty of Computer Science, University of Vienna, Austria ([email protected]);
(3) Heiner Stuckenschmidt[0000 −0002 −0209 −3859], Data and Web Science Group, University of Mannheim, Germany ([email protected]).
:::
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\
You May Also Like

Let insiders trade – Blockworks

XRP price rebounds off lower band as new XRP Ledger wallets surge to 8-month high
