

Matting Terbimbing Mask yang Teguh: Menguruskan Input Bising dan Kepelbagaian Objek
链接目录
摘要与 1. 引言
-
相关工作
-
MaGGIe
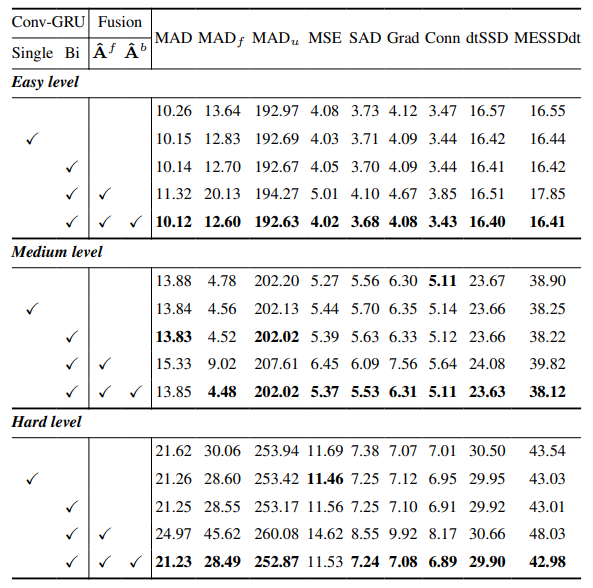
3.1. 高效遮罩引导实例抠图
3.2. 特征-遮罩时间一致性
-
实例抠图数据集
4.1. 图像实例抠图与 4.2. 视频实例抠图
-
实验
5.1. 图像数据预训练
5.2. 视频数据训练
-
讨论与参考文献
\ 补充材料
-
架构细节
-
图像抠图
8.1. 数据集生成与准备
8.2. 训练细节
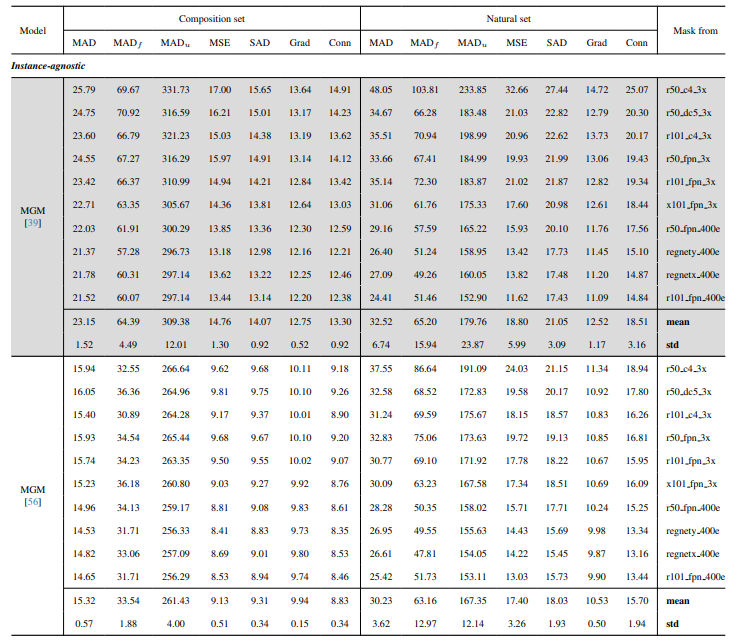
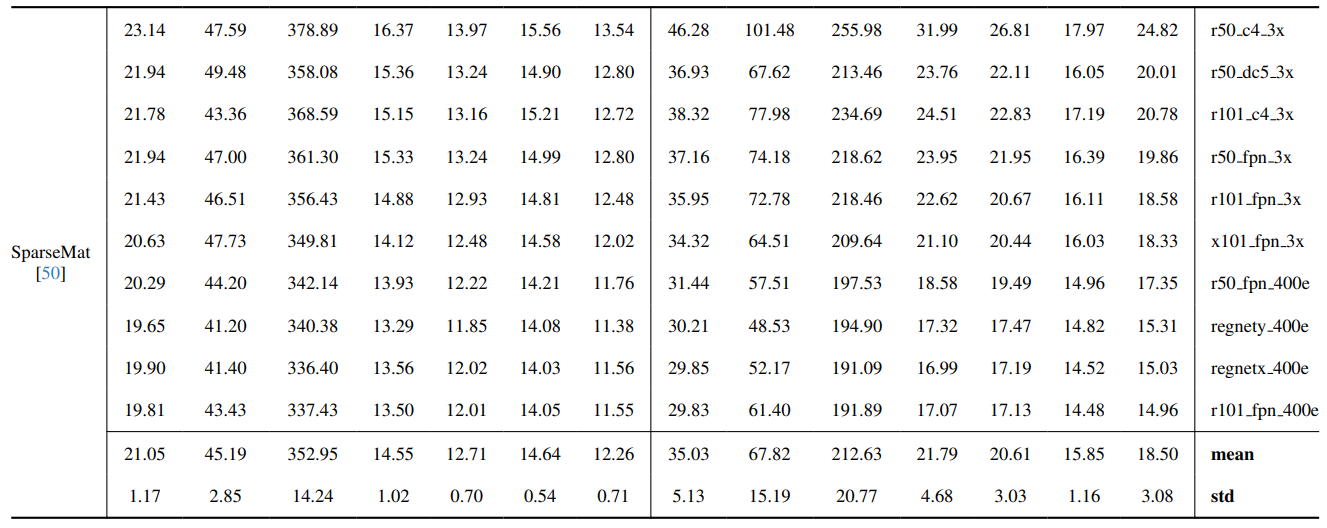
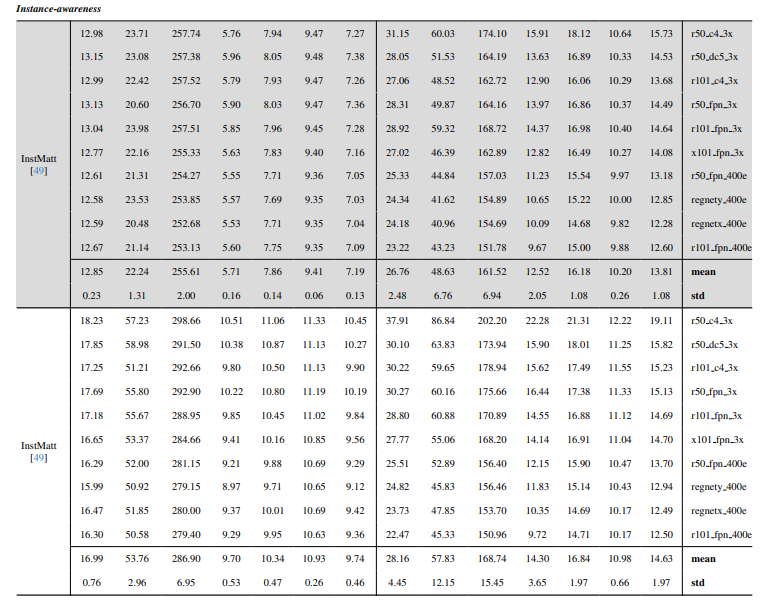
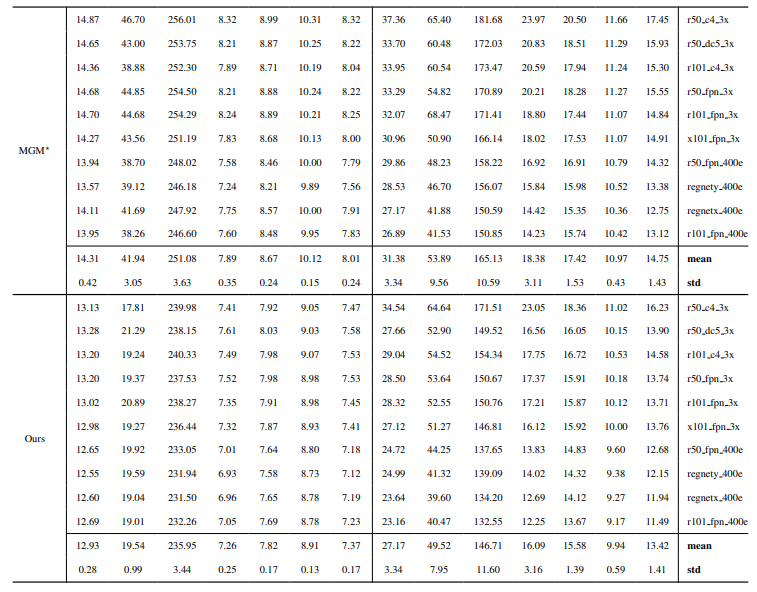
8.3. 定量细节
8.4. 自然图像的更多定性结果
-
视频抠图
9.1. 数据集生成
9.2. 训练细节
9.3. 定量细节
9.4. 更多定性结果
8.4. 自然图像的更多定性结果
图13展示了我们模型在具有挑战性场景中的表现,特别是在准确渲染头发区域方面。我们的框架在细节保留方面始终优于MGM⋆,尤其是在复杂的实例交互中。与InstMatt相比,我们的模型在模糊区域中表现出更优越的实例分离和细节准确性。
\ 图14和图15说明了我们的模型与先前工作在涉及多个实例的极端情况下的表现。虽然MGM⋆在密集实例场景中在噪声和准确性方面表现不佳,但我们的模型保持了高精度。InstMatt在没有额外训练数据的情况下,在这些复杂设置中显示出局限性。
\ 图16进一步展示了我们遮罩引导方法的稳健性。在这里,我们强调了MGM变体和SparseMat在预测遮罩输入中缺失部分时面临的挑战,而我们的模型解决了这个问题。然而,需要注意的是,我们的模型并非设计为人体实例分割网络。如图17所示,我们的框架遵循输入引导,即使同一遮罩中有多个实例,也能确保精确的alpha遮罩预测。
\ 最后,图12和图11强调了我们模型的泛化能力。该模型准确地从背景中提取人类主体和其他物体,展示了其在各种场景和物体类型中的多功能性。
\ 所有示例均为互联网图像,没有真实值,使用来自r101fpn400e的遮罩作为引导。
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info 作者:
(1) Chuong Huynh, University of Maryland, College Park ([email protected]);
(2) Seoung Wug Oh, Adobe Research (seoh,[email protected]);
(3) Abhinav Shrivastava, University of Maryland, College Park ([email protected]);
(4) Joon-Young Lee, Adobe Research ([email protected])。
:::
:::info 本论文可在arxiv上获取,采用CC by 4.0 Deed(署名4.0国际)许可证。
:::
\
您可能也会喜欢

XRP Ledger 在 24 小时内突破 250 万门槛,市场表现停滞

分析师认为这个新加密协议具有500%增长潜力,原因如下
